
Underhålls av: totte@informatik.umu.se
URL: http://www.informatik.umu.se/~totte/progutv/kursplan.html
Senast ändrad: 980115
Om kompendietGrundläggande C++Enkla datatyper, variabler och konstanter Pekare och strängar |
Klasser och objektArv och operatoröverlagring |
Länkar till källkodsfiler |
Detta kompendium är inte ett fristående läromedel utan är avsett att vara ett komplement till boken: Skansholm, Jan (1996). C++ direkt. Studentlitteratur, Lund.
Kompendiet har sitt ursprung i litteratur för kursmomentet Datakunskap II och senare kursmomentet C11.1, Programutveckling. Det är därför i vissa delar ganska elementärt eftersom det där riktat sig till studenter med ganska ringa erfarenhet av programmering. Kompendiet baserar sig från början på annan litteratur än ovan nämnda av Skansholm.
Avsikten med del 1 av kompendiet är i första rummet att stödja inlärningen av språket C++ och berör därför inte objektorienterad design och programmering i någon större utsträckning. Det närmast följande kapitlet är avsett främst som en kommenterad läsanvisning till delar av boken där viktiga punkter poängteras. De efterföljande kapitlen tar upp pekare och strängar samt klasser och objekt i C++.
Viktigt! I många programmeringsspråk, t ex Pascal görs ingen skillnad mellan små och stora bokstäver. I C++ skiljer vi på små och stora bokstäver för alla nyckelord och namn. Om man skall använda datatypen "char" så kan man inte skriva "Char" eller "CHAR", eftersom detta kommer att tolkas som något annat.
Hit hör typerna char, int, long (int) och short (int). Beträffande char se nedan. Ordet int kan utelämnas vid deklaration av long och short. Long är alltid 4 bytes och short 2 bytes. Hur typen int lagras beror på maskintyp. På en 16-bits maskin tex en PC under äldre Windows eller en äldre Macintosh är en int 2 bytes, på en 32-bits processor 4 bytes. Typen int kan ställa till problem vid flyttning av kod mellan olika maskiner med olika ordlängd. Ett bra tips är att oftast använda long som alltid är 4 bytes.
Lägg särskilt märke till hur division utförs på typen int. Om två heltal divideras i C++ så blir resultatet det som kallas en heltalsdivision. Det betyder att resultatet endast blir heltalsdelen av kvoten. Exempelvis blir 7/2 lika med 3. Notera också operatorn %. Denna används för att ta fram resten vid en heltalsdivision. Exempelvis blir 7%2 lika med 1, medan 6%2 blir 0. Märk också att resultatet av %-operatorn på negativa tal inte kan förutsägas eftersom det är beroende på maskinen du kör på.
Några kommentarer: Märk hur data automatiskt konverteras i blandade uttryck. Om int och float blandas blir resultatet alltid float. Endast när alla operander är typ int blir resultatet int.
Men, när ett resultat av typ float tilldelas till en variabel av typ int sker en konvertering till int. Därvid trunkeras decimalerna, dvs de kapas helt enkelt bort. Det sker alltså ingen avrundning. Antag variabeln int x. Båda uttrycken x = 12.11 och x = 12.79 ger som resultat att x innehåller 12.
Datatypen char
Denna används för att lagra enstaka tecken. Märk att en konstant av typen char anges med apostrofer, t ex 'A', 'f', '8' och '%'. Skilj detta ifrån ett eller flera tecken omgivna av citationstecken, vilket kallas för en sträng. Strängar skall vi behandla senare.
Typen char är inordnad under heltal vilket är helt korrekt. Den används oftast för att lagra tecken, men är i realiteten en en-bytes int. Det betyder att internt i programmet innehåller variabeln alltid ett talvärde, för teckenlagring dess teckenkod. Typen char betyder främst att värdet kommer att behandlas på särskilda sätt i samband med kommunikation med externa enheter som bildskärm tangentbord och skrivare. Några exempel på manipulationer med en charvariabel:
char tkn; tkn=67; cout << tkn; // skriver ut ett 'C' tkn++; // tkn ökas med 1 cout << tkn; // skriver ut ett 'D' if (tkn < 65) // alternativt if (tkn < 'A') cout << "Ej en bokstav";
Notera också att det finns ett antal speciella teckenkonstanter, kallade "escape-sekvenser". I datavärlden menar vi med escape-sekvens att ett eller flera tecken förhindras att tolkas som vanligt, genom att vi sätter ett särskilt tecken före. Tecknet \ (ofta kallad backslash) är ett sådant escapetecken i C++. Det används här för att efterföljande tecken skall få en särskild mening.
En sådan konstant som används ofta i C++ är \0 (noll) som står för ASCII-noll. Detta används vid stränghantering.
Tecknet newline, '\n', används i C++ för att skapa en radmatning på skärmen vid utskrift. Escape-sekvenser kan användas som egna teckenkonstanter, men kan också bakas in i strängar varför man t ex kan lägga in radmatningar inuti en sträng som skall skrivas ut.
En ytterligare kommentar vad gäller teckenvariabler: Det beror på ditt system hur detta behandlar de svenska tecknen å, ä och ö. I vissa system kan dessa tecken representeras i typen char i andra inte. Detta beror på följande: En char är en byte lång. Men en char är inte bara ett tecken det är också en heltalsvariabel som kan innehålla små tal. När du matar in ett tecken i en char-variabel kommer den i verkligheten att innehålla talets ordningsnummer i det teckenkodsystem som används på din dator. I heltals variabler används oftast en bit till att representera om det är ett positivt eller negativt tal. Datatypen är då signed, t ex signed int. Om alla bitarna används för talvärdet kan endast positiva tal representeras. En sådan typ kallas då unsigned.
Så är också fallet med typen char, som vanligen har varit just signed char. I så fall kan bara tal mellan 0 - 127 representeras. I persondatorer och många andra moderna system används 8 bits för att representera ett tecken, vi har då tillgång till koderna 0 - 255. I vissa C++ kan det ställas in vad en char skall vara och det beror då på denna inställning hur svenska tecken hanteras. I vissa system kan även en signed char användas för tecken med kod större än 127. Trots att koden numeriskt tolkas som ett negativt tal så tolkas den av alla funktioner som behandlar char som den korrekta teckenkoden.
Om du inte är helt klar över hur det förhåller sig på ditt system, undvik de svenska tecknen tills du har blivit säkrare och kan testa själv.
En mängd funktioner finns för att testa vad ett tecken är och för att omvandla tecken. Några av de mest använda visas här. Funktionerna förutsätter följande include-sats (se nedan om preprocessordirektiv):
#include <ctype.h>
Följande deklaration förutsätts här:
char c; isdigit(c) sann om c innehåller en siffra isalpha(c) sann om c innehåller en bokstav isspace(c) sann om c innehåller ett mellanslag isuppper(c) sann om c innehåller en stor bokstav islower(c) sann om c innehåller en liten bokstav c=toupper(c) om c innehåller en liten bokstav omvandlas den till stor och returneras c=tolower(c) om c innehåller en stor bokstav omvandlas den till liten och returneras
En kommentar till detta: De teckentestfunktioner som finns i standardbiblioteket ctype är också beroende av vilken teckenkodsekvens som används på ditt system. Lita därför inte på att funktionerna isalpha och isalnum ger rätt resultat med svenska bokstäver, ens om ditt system i övrigt kan hantera dessa. Testa gärna detta med ett litet program.
I en uppräknad typ skapar man själv en lista av värden som sedan kan användas för olika ändamål. Vanligast är att de används för indikatorer och väljarvärden av olika slag. Om dessa talas i kapitel 7 i boken. Exempel:
enum colors{red, blue, green, yellow};
Namnet "colors" står nu för en datatyp vars värden kan vara endast de inom klammerna angivna färgnamnen. Namnen representerar i själva verket varsitt heltalsvärde där red är 0, blue är 1, osv. Man kan också ge värden explicit:
enum bits{bit1=1, bit2=2, bit3=4, bit4=8};
Det finns inte någon särskild boolsk datatyp i C++. För boolska värden används heltal, där regeln är att 0 är falskt medan icke 0 är sant. Vanligen används 1 för sant. Med en uppräknad typ kan man dock lätt skapa sin egen boolean:
enum boolean {false, true};
En annan variant är att använda fördefinierade namn (se nästa avsnitt i kompendiet):
#define FALSE 0 #define TRUE 1 #define BOOLEAN char
Med ordnad typ (ordinal type) menas följande: Datatypen består av distinkta uppräkningsbara värden, vilket är fallet med int och char. De reella talen, dvs alla decimaltal är ju en kontinuerlig skala där vi genom att lägga till fler och fler decimaler kan hitta oändligt många värden inom även ett litet intervall. Vi säger därför att typen float inte är en ordnad typ.
Eriksson sid 154 - 157
Dessa kallas för preprocessordirektiv, eftersom de bearbetas av en särskild förprocessor som hör till kompilatorn. Dessa direktiv är alla rader som börjar med tecknet "#". Vanligast av dessa är s.k. include-satser.
Ditt färdigkompilerade program består av mycket mer än bara det som härstammar från din egen C++kod. Efter kompileringen länkas en mängd färdiga rutiner till för t ex in- och utmatning. Men de färdiga rutinerna kräver ofta också att det finns en del deklarationer gjorda i förväg. Dessa finns i det som kallas "header-filer", vilket är färdiga stycken av C++kod. Sådana inkluderas i ditt program av satser av typen:
#include <iostream.h>
< och > talar om att filen iostream.h finns i ett standardbibliotek för ditt system.
Man kan också inkludera egna källkodsfiler i sitt program. För C++ är det mycket vanligt att man gör så med typ- och klassdeklarationer, när man bygger program som består av flera separat kompilerade moduler. Exempel:
#include "dekl1.h"
Citationstecknen talar om att filen skall sökas i samma bibliotek som filen satsen står i. Man kan även skriva en fullständig sökväg här.
Kompileringsdirektiv kan också användas för att definiera namn.
#define MAX 40
Satsen definierar ordet MAX till att i all programtext därefter stå för värdet 40, dvs det fungerar som en namngiven konstant.
Ett uttryck är i programmeringssammanhang varje konstruktion som har ett eget värde. Exempel på uttryck
2.0 //konstant värde tal1 //tal1 är namnet på en variabel tal1 + 15 // addition av variabel och konstant värde tal2 + tal2 - tal3 // beräkning med flera variabler
Ett uttryck är alltid av en viss datatyp och kan då tilldelas till en variabel som har denna typ. Om alla deluttrycken är av typ int kan uttrycket tilldelas till en variabel av samma typ. Som vi skall se senare kan olika numeriska typer också tilldelas till varandra men då med risk för vissa konsekvenser.
Tilldelning görs med ett enkelt likhetstecken t ex
summa = tal1 + 4 // summa och tal1 är variabler av typen int
Observera att även tilldelningen är ett uttryck som har ett värde nämligen värdet av det som tilldelas.
Viktigt! Skilj tilldelningstecknet = från jämförelseoperatorn ==. Att använda tilldelningstecknet i ett villkor är nämligen inte syntaxfel men man får villkor som dels inte fungerar i sig och dels kan ha svårupptäckta följdeffekter.
Nedan tas upp vissa detaljer som kräver särskild uppmärksamhet.
Var särskilt uppmärksam på i vilken ordning logiska uttryck utvärderas. Bilaga 2 i detta kompendium innehåller en komplett prioritetstabell . Notera också vikten av att använda parenteser på rätt sätt. Kom ihåg: Överflödiga parenteser gör ingen skada och kan ofta göra uttrycken mycket lättare att läsa och förstå. Viktigt: Det förtjänar att upprepas skillnaden mellan = och ==. = är tilldelning medan == är likhetsoperator. Förväxling av dessa i villkor leder vanligen inte till kompileringsfel utan till felaktiga beteenden som kan vara mycket svåra att härleda.
Switch-satsen är särskilt utformad för att utföra flervägsval. Den kräver en viss eftertanke. Du kan se switch-satsen som att det finns två "kolumner" i exekveringsflödet. I den vänstra finns "case-etiketterna" och i den högra andra satser. Efter att väljarvärdet i den inledande raden, huvudet där ordet "switch" står, har avlästs går exekveringen in i den vänstra kolumnen. Om en etikett hittas där värdet är detsamma som i väljarvärdet leds exekveringen över till den högra kolumnen och börjar exekvera satserna där, från samma "nivå" som case-etiketten. Exekveringen fortsätter tills ordet "break" påträffas. När detta sker hoppar exekveringen ur switch-satsen. Observera att om inget break finns fortsätter exekveringen av nedanstående exekveringssatser helt oberoende av att det finns fler case-etiketter "till vänster". I nedanstående exempel kommer variabeln tal1 att bli 20 om val innehåller 5. Eftersom inget break finns efter nästa gren kommer tal 1 att tilldelas först 40 och sedan omedelbart 50 om val innehåller 6.
int val = 5;
switch (val){
case 5 : tal1 = 20;
break;
case 6 : tal1 = 40
default : tal1 = 50
}
Märk att for-loopen egentligen bara är ett annat sätt att skriva en while-loop. Studera följande exempel:
for (i=1; i<10; i++) cout << i << endl;
Observera särskilt: I parentesen efter for finns tre delar. Den första görs innan loopen startar. Den andra delen är ett villkor som är exakt detsamma som skulle använts i en while-loop. Den tredje delen är uttryck som utförs varje varv, efter att samtliga satser i loop-blocket utförts.
Nästan alla programspråk har möjligheter att dela in programkoden i namngivna separata delar som fungerar oberoende av varandra. På så sätt kan vi utifrån ett strukturerat problem skriva ett program som följer den struktur som problemanalysen har givit. I C++ kallar vi sådana programdelar för funktioner. (Senare skall vi se hur man också kan samla flera funktioner tillsammans i större block kallade klasser)
I mycket små och enkla program finns en enda funktion, med namnet "main". Denna funktion måste alltid finnas eftersom den utgör startpunkten för varje programkörning. De flesta program består emellertid av flera funktioner.
Liksom variabler har även funktioner en datatyp och ett namn. Dessa måste deklareras innan de används, dvs anropas. En fristående funktionsdeklaration kallas prototyp. Den faktiska koden för funktionen kallas dess definition. Deklarationen tjänar syftet att göra funktionen med datatyp och eventuella parametrars datatyper kända för kompilatorn, så att anropet kan utvärderas rätt.
Definitionen kan också utgöra deklaration, nämligen om funktionen definieras före den plats där den först anropas. Normalt i C++ använder man alltid prototyper som då oftast placeras i särskilda "header"-filer som sedan inkluderas på de platser de behövs med #include-satser.
Ett funktionsnamn kan förekomma i tre olika roller, i prototyp, i anrop och i funktionsdefinition. Prototypen för funktionen måste alltid komma före alla andra omnämnanden i programtexten. Definitionen kan sedan i övrigt förekomma var som helst liksom ett anrop kan ske var som helst efter prototypen.
Returvärden skapas med kommandot return När en return-sats påträffas avslutas funktionen, ett återhopp sker till den plats där anropet skedde. När ett värde följer efter ordet return betyder det att funktionen ges just detta värde. Funktionen kan alltså i den sats där den anropas användas som ett uttryck med ett värde. Märk också att man kan hoppa ur en funktion var som helst med return och att det kan finnas flera returnsatser i samma funktion, varvid endast den första som nås under exekveringen utförs. Om en funktion saknar return-sats (vilket inte tillåts i alla system) returnerar den vid funktionskroppens slut.
Void är en typ som används för att deklarera att en funktion inte returnerar något värde. I en funktion av detta slag kan return endast användas utan efterföljande värde och utför då endast återhopp.
En kommentar: Det förekommer att man ser program där funktionen main har typen void och saknar return-sats. Det är inte alla system som accepterar detta utan kräver att main skall ha typen int och returnera ett värde. Det returnerade värdet används då som statusvärde till operativsystemet vid programavslut.
Parametrar, även kallade argument är i första hand vägen in för data.
int sqr(int x){
return x * x;
}
int main(){
int a;
a = 2;
a = sqr(a)
cout << a;
}
x i funktionen sqr kallas den formella parametern. I anropet av funktionen sqr, a = sqr(a), ser vi hur det i parentesen står namnet a, vilket är namnet på en i main lokal variabel. Detta är den aktuella parametern. Vad som händer vid anropet är att den aktuella parameterns värde kopieras in i den formella parameterns datautrymme så att x får samma värde som a. De är däremot helt skilda åt i programmets minnesutrymme.
En parameter av detta slag som endast för in ett värde i en funktion kallas sammanfattande för värdeparameter.
Tidigare har vi sett parametrar som vägen in i en funktion och returvärden som vägen ut. Problemet är att det inte går att returnera flera värden samtidigt. Vill vi få ut flera värden så måste vi använda oss av en särskild typ av parametrar, referensparamerar.
De värdeparametrar som vi studerat tidigare fungerar så att en del av minnet reserveras för parametern och dit kopieras det värde som sänds in. För referensparametrar kopieras inte värdet. Det som händer är att funktionen i stället får en adress till den anropande variabeln, en referens. Så när parametern ändras inuti funktionen så sker faktiskt ändringen direkt i den variabel som är den aktuella parametern alltså den anropande.
En referensparameter deklareras genom att ett &-tecken skrivs direkt efter datatypen innan namnet på parametern deklareras.
Notera särskilt att för referensparametrar kan endast variabler användas som aktuella parametrar.
void sqr(int& x){
x = x * x;
}
int main(){
int a;
a = 2;
sqr(a)
cout << a;
}
I exemplet anropas sqr med den aktuella parametern a. Den formella parametern x är en referensparameter, vilket innebär att den tjänstgör som ett alias för a. Det betyder att multiplikationen inuti sqr faktiskt utförs direkt med variabeln a och resultatet placeras direkt i a. Detta medför då att utifrån betraktat förefaller det som att värdet skickas både in och sedan tillbaka ut.
Det finns en mängd standardfunktioner tillgängliga. C++ är helt bakåtkompatibelt med ANSI C här vilket medför att alla dess biblioteksrutiner finns tillgängliga. Konsultera manualen för din C++ där alla standardfunktioner bör finnas beskrivna.
Ett viktigt påpekande: När standardfunktioner används förutsätter detta alltid att en header-fil inkluderas, där definitioner och deklarationer för funktionerna finns. Vilken header som krävs anges i manualen. Detta visas också i bilaga 1 för de funktioner som är med där. T ex kräver stränghantering:
#include <string.h>
I varje system finns också en uppsättning plattformsberoende funktioner för t ex hantering av olika operativsystemfunktioner, gränssnitt, mm. Sådana plattformsberoende rutiner bör användas med urskiljning, eftersom de åstadkommer att koden inte blir portabel mellan olika plattformar.
Notera särskilt att i C++ kan man inte specificera vilket intervall som index skall ha utan endast vektorns storlek. Index börjar alltid med noll för första elementet och högsta index är därmed (storleken - 1). Det finns heller ingen inbyggd kontroll av att index är inom tillåtet intervall.
Notera hur vektorer kan initieras vid deklarationen, varvid man inte behöver ange storleken.
long heltal[]={2,34,5,6,71};
Ovanstående deklarerar en vektor med storleken 5 med de angivna värdena. Observera att detta endast kan göras som initiering vid deklarationen, det går alltså inte senare att tilldela nya värden till vektorn på detta sätt.
Vektorer i C++ är tätt kopplade till pekare. Se avsnittet om pekare nedan
Ström (stream) är en sekvens av tecken som strömmar in till eller ut ur programmet. Du har hittills använt dig av standard in- och standard ut-strömmarna som i c++ kallas "cin" respektive "cout". Vad du gjort när du skrivit t ex cout << "Hej!" är att skicka texten "Hej" till standard ut-strömmen vilket är det samma som till bildskärmen. cin står då för tangentbordet.
En ström kan också vara kopplad till en fil.
En fil är en lagrad datamängd, oftast på en hårddisk eller diskett när du använder en persondator. En fil kan ses som en sekvens av bytes. I ett C++program kan vi koppla en sådan extern fil till en ström i programmet. Filens namn är det som du ser när du listar innehållet i en katalog eller mapp. Det namnet existerar så länge filen finns. Strömmens namn är internt i ditt C++program och det namnet är bara verksamt när du kör programmet.
I filer som innehåller text är oftast innehållet organiserat i rader. En rad består av inget eller flera tecken åtföljt av specialtecknet newline. I C++ används konstanten '\n' för att beteckna detta tecken. En rad med endast ett newlinetecken kallas en blankrad. Detta är precis samma sak som du ser vid utskrifter på bildskärmen, endl som du använt många gånger skickar just ett newline-tecken till skärmen för att en ny rad skall påbörjas.
#include <iostream.h>
#include <fstream.h>
int main()
{
ifstream ins;
ofstream uts;
char buff[80];
ins.open("infil.txt");
if (!ins){
cerr << "Infil kunde inte öppnas";
return -1;
}
uts.open("utfil.txt");
// felhantering bör finnas även här
ins >> buff;
while (!ins.eof()){
uts << buff;
ins >> buff;
}
ins.close();
uts.close();
return 0;
}
För att det skall gå att arbeta med filer måste fstream.h inkluderas. Strömmen måste sedan deklareras. Du hittar deklarationen ifstream ins;. Det betyder att en ström har deklarerats som heter ins och det är en ström för en infil (if = infile). Lite längre ned hittar du ins.open ("infil.txt"). Det är här som kopplingen sker. Notera sedan felhanteringen där vi använder not-operatorn ! för att testa om filen öppnades korrekt. Om inte avslutar vi genom att returnera från main. Felhanteringen kan också göras med hjälp av funktioner, bl a fail och bad.
Alla funktioner som arbetar på strömmar skrivs som illustreras i exemplet med strömnamn.funktionsnamn. Orsaken är att de är medlemsfunktioner i fördefinierade klasser, något som kommer att tas upp senare.
Vad som gjorts är alltså att strömmen ins nu är kopplad till filen infil.txt. Det betyder att om vi tar ut tecken från strömmen så kommer dessa tecken att hämtas från den kopplade filen.
Vi förfar på samma sätt med utströmmen uts som kopplas till utfil.txt.
Du kan läsa från en inström som är kopplad till en fil på samma sätt som du läser från tangentbordet. ins >> buff läser sålunda ett antal tecken från strömmen och därmed från filen och placerar det i variabeln buff som vi är en strängvariabel. Ett problem här är att vi med >> operatorn alltid läser högst fram till nästa vita tecken och i nästa läsning börjar på nästkommande ej vita tecken. Det vi får i utfil.txt är alltså alla ord i infilen i en rad utan mellanslag eller radbrytningar.
Ett annat problem är att vi vet inte hur många tecken som finns i filen. Därför finns funktionen eof () som i detta fall skrivs ins.eof ().
En bättre lösning på problemet att kopiera en textfil är följande:
#include <iostream.h>
#include <fstream.h>
#define BUFFLEN 80
int main()
{
ifstream ins;
ofstream uts;
char buff[BUFFLEN];
ins.open("infil.txt");
if (!ins){
cerr << "Infil kunde inte öppnas";
return -1;
}
uts.open("utfil.txt");
// felhantering bör finnas även här
ins.getline(buff,BUFFLEN);
while (!ins.eof()){
uts << buff << endl;
ins.getline(buff,BUFFLEN);
}
ins.close();
uts.close();
return 0;
}
Notera funktionen getline här kopplad till ins. Första argumentet är mottagande variabel, andra längden på denna variabel. Ett tredje argument kan anges som anger vilket tecken som avbryter läsning. Defaultvärde för tredje argumentet är '\n'. getline läser alltså en rad i taget till buff, vilken sedan skrivs ut till utfilen med << operatorn.
Pekare deklareras som alla andra variabler med en datatyp. Denna typ talar då om vilken typ av data som pekaren kan referera till, inte hur själva pekaren skall se ut. Exempel:
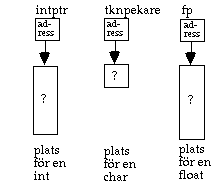
int *intptr; char *tknpekare; float *fp;

Dessa tre deklarationer skapar tre pekare, till vardera typen int, char och float. Det som gör dem till pekare är stjärnan. Obs att man ofta ser syntaxen int* intptr, vilket inte gör någon skillnad. Deklarationerna skapar enbart pekarna själva, det finns ännu inget utrymme för att lagra något int-, char- eller floatvärde. Pekarna är odefinierade i nuläget. Bilden visar läget med tre pekarvariabler som inte refererar till någonting alls.
För att skapa det utrymme vi behöver använder vi den speciella operatorn new. Denna anropar operativsystemet med en begäran om så mycket minne som behövs för datatypen ifråga. Vi får en bit av minnet där det finns ledigt och en adress till denna plats.
intptr = new int; tknpekare = new char; fp = new float;
Bilden visar läget efter new-satserna. Pekarna innehåller nu varsin adress till olika platser i minnet. Själva behöver vi aldrig hålla reda på dessa adresser utan vi kan nu via pekarna hantera minnesutrymmena vi fått. Medan pekarna är definierade nu så är våra nya minnesutrymmen däremot odefinierade.
Observera hur i newsatsen vi skrev att t ex fp = new float. I och med att vi använde pekarnas namn på detta sätt så menade vi pekarvariablerna själva, dvs vi ville tilldela adresserna direkt till pekarna. För att i stället komma åt det som pekarna refererar till sätter vi dit en stjärna före namnet.
*intptr = 125; *tknpekare = 'G'; *fp = 22.575
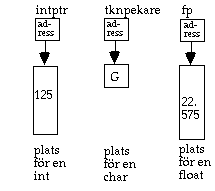
Tilldelningarna ovan tilldelar värden till de minnesutrymmen som pekarna pekar på. Att sätta en * före pekarnamnet får effekten att pekarnamnet fås att referera till minnesutrymmet som pekas på istället för pekaren själv. Detta brukar kallas för dereferencing.
Vi kan på samma sätt dereferera pekare för att hämta värden.
cout << *intptr; // skriver ut talet 125 cout << *tknpekare; // skriver ut tecknet 'G' cout << *fp; // skriver ut talet 22.575
Det är inte syntaxfel att skriva:
cout << intptr;
Däremot leder det inte till att några normalt begripliga data skrivs ut. Det som fås är det numeriska värdet av minnesadressen i pekaren själv som ett hexadecimalt tal. Detta kan möjligen vara till nytta vid felsökning i avancerade systemprogram och likande.
I C++ har pekare och vektorer ett starkt samband. Man kan säga att en vektor egentligen är en pekare till en sekvens av minneselement. Detta visas av att vektornamnet, utan indexering, faktiskt representerar adressen till vektorns första element. Följande lilla övning visar detta.
int *talp, talv[10] = {1, 3, 9, 4, 6};
talp = talv; //pek talp får adressen till talv:s första element
cout << *talp; // skriver ut talet 1
cout talp[2]; //skriver ut talet 9
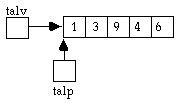
Vi kan alltså betrakta namnet på vektorn som en konstant pekare till vektorns första element. Märk också att pekaren talp kan lika väl behandlas som vektor med indexering när den fått adressen till vektorn talv.
Vi kan dessutom använda oss av pekararitmetik, där vi genom att addera och subtrahera kan flytta pekaren i vektorn elementvis.
talp++; //flyttar fram talp ett int-elemnet i vektorn cout << *talp // skriver ut talet 3 talp += 2; // flyttar fram talp 2 element cout *talp // skriver ut talet 4
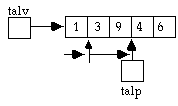
talp -=3; // flyttar tillbaka talp 3 element cout *talp // skriver ut talet 1
Vid pekararitmetik flyttas pekaren alltid storleken av den aktuella datatypen när vi ökar eller minskar med 1. Notera att endast subtraktion och addition är tillåtna operationer.
I många fall är det mycket bra att inte behöva deklarera en vektor med sin storlek förrän vid exekveringen. Typiskt exempel är när en datamängd skall inmatas och användaren först får ange hur många värden som skall in. Vi kan då i förväg deklarera en pekare enbart och sedan dynamiskt allokera en vektor. Observera här hur pekarens namn sedan kan användas som ett vektornamn med indexering.
#include <iostream.h>
int main()
{
struct post{
int nr;
char namn[20];
} *postvekt; // deklaration av en pekare till en struct
int antal, i;
cin >> antal;
postvekt = new post[antal]; // allokerar en ny vektor med antal element
for (i=0; i < antal; i++){
cout << "Namn: ";
postvekt[i].nr = i + 1;
cin >> postvekt[i].namn; // läser in värden i alla element
}
cout << endl;
for (i=0; i < antal; i++)
cout << postvekt[i].namn << " " << postvekt[i].nr << endl;
cout << endl;
return 0;
}
En sträng i programmeringssammanhang är helt enkelt en följd av godtyckliga tecken som behandlas som en enhet. Du har redan använt dig av strängar nämligen vid utskrift där du mellan citationstecken skrivit diverse texter. Det kallar vi för strängkonstanter. Strängar kan också hanteras i variabler. En variabel för en sträng är en vektor av typen char. En sträng kan vara av variabel längd och behöver inte fylla vektorn. En sträng avslutas alltid genom en s k null-byte, dvs en byte som har teckenkoden noll. Det betyder att en sträng maximalt får ha längden vektorns längd minus 1. En vektor med 20 element kan innehålla strängar med högsta längd 19.
En sträng kan initieras vid deklarationen:
char str[]="ABCDE"
Här skapas en vektor av char med sex element, fem för tecknen ABCDE och ett sjätte för avslutande null-byte. Observera att det endast är vid initiering som man på det sättet kan göra en tilldelning. Det går alltså inte sedan att tilldela en annan sträng till samma vektor på detta sätt. Märk att om ingen storlek anges på vektorn vid initieringen så blir den så lång som strängen plus ett element för nullbyten.
Studera särskilt noga inmatning av strängar med cin och notera att cin alltid slutar läsning av sträng vid första blanka tecken. Om du vill läsa in strängar som innehåller mellanslag måste funktionen getline användas. Exempel:
const len = 40 char namn[len]; cin.getline(namn,len);
Getline läser högst det antal tecken som anges av len - 1. På så vis finns plats för avslutande nullbyte i vektorn namn. Matas färre tecken in läses till första radslutstecken.
En mängd funktioner för att hantera strängar finns i standardbiblioteket string. Här tas upp några av de mest använda och nödvändiga av dessa. Funktionerna kräver följande include-sats.
#include <string.h>
Vi förutsätter följande deklarationer:
char s1[40], s2[20]; int n, res; strcpy(s2,"abcdefg") Kopierar källsträngen i arg 2 till mottagaren i arg 1, dvs "abcdefg" till s2. strcpy(s1,s2) Kopierar innehåll i s2 till s1 strncpy(s1,s2,n) Kopierar innehåll i s2 till s1, dock max n tkn strcat(s1,s2) Lägger ihop s1 och s2 och placerar resultatet i s1 strncat(s1,s2,n) Lägger ihop s1 och s2 och placerar resultatet i s1, dock max n tkn från s2 res=strcmp(s1,s2) Alfanumerisk jämförelse av s1 och s2. Om s1>s2 blir res positivt, om s1 == s2 blir res 0, om s1<s2 blir res negativt. res=strncmp(s1,s2,n) Som strcmp men max n tkn jämförs res=strlen(s1) res blir längden av s1 exklusive avslutande null-byte
Du har tidigare sett hur strängar lagras i en vektor av typ char, där slutet på strängen anges av en byte som är noll, i C++ representerat av '\0'. En vektor av char är en följd av bytes vars början utgörs av en adress. Vektornamnet utan index representerar adressen till vektorn. Därmed kan följande definition göras för strängimplementationen i C++:
Strängen implementeras som en följd av tecken, vars början utgörs av en adress, och vars slut utgörs av en ascii-noll, som inte anses tillhöra strängen. Till implementationen hör en uppsättning funktioner och operatorer som utgör de metoder som kan används på strängen.
Det intressanta här är att adressen till början inte måste sammanfalla med en vektors första byte. Det kan vara vilken adress som helst som pekar mot ett element av rätt typ.Tillsammans med vad vi vet om sambandet mellan pekare och vektorer ger detta intressanta möjligheter. Studera följande kodavsnitt:
char str[] = "ABCDE", *st1; st1 = str + 2; // pekararitmetik st2 sätts 2 tkn fram i strängen cout << st1; // CDE skrivs ut cout << str // ABCDE skrivs ut
Vi använder oss här av att en strängs början är en adress. Genom att sätta st1 till str + 2 skapar vi en adress som pekar på det tredje tecknet i strängen str. Vi ha alltså skapat en ny sträng st1 som innehåller tecknen "CDE". Notera att vi inte använder någon * före namnet st1 i cout-satsen. Ascii-noll finns efter sista tecknet, eftersom det läggs dit automatiskt vid initieringen av strängen i deklarationen.
cout << *st1 // C skrivs ut
Om vi använder * derefereras pekaren från pekare till char till just bara typen char, dvs ett tecken och det tecken som st1 pekar på skrivs ut. När vi inte derefererar pekaren tolkas namnet i stället som adressen till en sträng av cout och vad som då sker är att vid adressen börjar tecken för tecken plockas och skickas till bildskärmen tills en ascii-noll påträffas. Det är alltså exakt samma process som sker när str skickas till cout.
Låt oss se på en vanlig metod att bearbeta tecknen i en sträng, med en loop som flyttar en pekare farmåt tecken för tecken. Här vill vi ändra alla stora bokstäver till små, och använder funktionerna isupper för att testa om det är en stor bokstav och tolower för att konvertera tecken.
for (st1=str; *st1 != '\0'; st1++) if (isupper (*st1) *st1 = tolower(*st1);
Ytterligare ett exempel: Vi vill skriva en funktion som kortar av en sträng till önskat antal tecken förutsatt att den är längre så.
void strcut (char *st, int n){
char *s = st;
while (*s != '\0') // s flyttas fram till strängslutet
s++;
if (n < s-st){ // pekar aritmetik, s - st ger längden
s = st + n; // sätter s på tecknet efter önskad längd
*s = '\0'; // genom att sätta dit '\0' skapas nytt strängslut
}
}
Här ser du flera exempel på hur vi kan använda pekararitmetik, både för att flytta pekare och för att finna avståndet mellan två pekare.Jämför också med nästa avsnitt om vektorer som parametrar, de skickas alltid via referens, just därför att det är en adress vi skickar in. Den anropande variabeln förändras alltså direkt av de åtgärder vi vidtar på st i funktionen.
En kommentar: Vi kunde givetvis använt strlen för att söka stränglängden, men då hade det varit nödvändigt att inkludera string.h i varje program där funktionen används. Med denna metod slipper vi detta.
En sträng är som sagts ovan en teckenföljd som startar vid en adress och avslutas men '\0'. När en sträng sänds som parameter till en funktion sker detta genom att strängens adress skickas. Som sades om vektorer ovan så representerar namnet på en vektor alltid adressen till vektorn. Likaså tolkas en konstantsträng som en adress till strängens minnesutrymme. Därför kan man använda en pekare till char som formell parameter för strängar. I följande enkla exempel skickas rad till prinstr som tar emot adressen i pekaren str och därefter vid utskriften hämtar data via pekaren direkt från rad i main.
void printstr(char *str){
cout << str << endl;
}
int main(){
char rad[80];
cin.getline(rad,80);
printstr(rad);
}
Notera att detta betyder att när en sträng skickas som parameter så sker detta alltid som en referensparameter fast det sker explicit pekarhantering istället för den dolda hantering som ligger bakom referensdeklaration.
Samma som gäller för strängar gäller för alla typer av vektorer, här exemplifierat med en int-vektor:
void printvekt(int *v, int sz){
for(int i=0; i < sz; i++)
cout << v[i] << endl;
}
int main(){
char vekt[5];
for(int i=0; i < 5; i++){
cout << "Tal " << i <<": ";
cin >> vekt[i];
}
printvekt(vekt,5);
}
I sin allmänna betydelse är ett objekt något som existerar och som har egenskaper. Ofta tänker vi på konkreta ting när vi talar om objekt, t ex en hammare som har en mängd egenskaper som mått, vikt, färg, material, etc. Men vi tänker inte på en hammare bara i termer av sådana egenskaper utan vår främsta grund för att anse att det är en hammare är vad vi kan göra med den, slå, spika, dra ut spik, etc. Därmed har vi sagt att ett objekt bestämmer vi i termer av egenskaper (även kallade attribut) och operationer. (Vi skall inte här dra upp den filosofiska diskussionen om objekt, vilken omfattar hyllkilometer) Nu behöver ett objekt inte bara vara fysiska ting utan även sådant som idéer, matematiska formler, logiska satser, etc, kan ses som objekt, just därför att de har vissa egenskaper och att vissa operationer kan utföras på eller med dem.
När vi talade om hammaren ovan så menade vi just en särskild hammare av en viss typ med en bestämd vikt t. ex. Men när vi använder ordet "hammare" menar vi ofta inte den särskilda hammaren utan det allmänna begreppet "hammare" Ett objekt är alltså det enskilda föremålet hammare om vilken vi vet, inte bara att den har en viss vikt, utan också vad den vikten är. Om allmänbegreppet "hammare" vet vi att varje hammare har en vikt men inte vad den är i det enskilda fallet. I den terminologi vi använder här kan vi säga att allmänbegreppet "hammare" representerar en klass av objekt, nämligen klassen "hammare".
En klass är därför kan vi säga en deklaration av en typ av objekt, där vi noga specificerar vilken sorts egenskaper som skall känneteckna de enskilda objekten. Eftersom hammare kan se väldigt olika ut så måste vi noga fundera igenom vilka typer av egenskaper som är gemensamma för alla hammare. Vi väljer alltså ut vissa typiska drag för det vi menar utgör en hammare och vad vi behöver veta om en hammare. Tillsammans med en beskrivning av de operationer som vi kan utföra med alla hammare utgör det en definition av klassen hammare.
Ett enskilt objekt beskrivet i de termer som anges av en klass kallar vi för en instans av klassen. En enskild hammare är alltså först och främst ett objekt. Har vi definierat en klass hammare med en uppsättning attribut och operationer och använder oss av denna begreppsram för att bekriva vårt objekt hammaren så är hammaren en instans av klassen. Vi kan alltså säga att "instans" och "objekt" i detta sammanhang är synonymer.
I C++ har vi en mekanism för att skapa klasser och objekt. Fundera först över den datatyp som kallas struct i C++. Den ger ju möjlighet att definiera egenskaper hos objekt. Vi kan t ex skapa en post "produkt" som innefattar t ex produktnr, benämning, pris, leveranstid, etc. Allt detta är då egenskaper som vi bedömer som nödvändiga för att bestämma en produkt i det sammahang som råder. Om vi har ett register med några sådana poster så utgör varje enskild post bekrivningen av ett objekt, medan deklarationen av struct produkt är en beskrivning av klassen produkter. Nu vet vi då att för sådana poster kan vi skapa ett antal olika funktioner för att manipulera data. Vi kan t ex ha funktionerna nyprod(), uppdatpris() och skrivutprod(). Dessa funktioner är inte knutna till posterna på annat sätt än genom vår egen namngivning och användning av dem, trots att de är avsedda som operationer på just de objekten som ingår i klassen.
Men genom att använda oss av C++konstruktionen class kan vi göra den här direkta kopplingen. Enkelt kan man säga att en klass är en slags post som inte bara kan innehålla egenskaper utan också operationer, dvs C++funktioner. Jämför nu nedanstående deklarationer:
//------------------------------------------------------------------------
struct produkt{ // dekl av en datatyp, en "klass" av produkter
int prodnr;
char benamning[20];
float pris;
int levtid;
};
produkt prodpost; // dekl av en variabel, en bestämd produkt
//------------------------------------------------------------------------
class produkt{ // dekl av en klass, en datatyp för produkter
public:
void nyprod(char*); // medlemsfunktioner
void uppdat(float, int);
void skrivutprod();
float ge_pris ();
private:
int prodnr; // datamedlemmar
char benamning[20];
float pris;
int levtid;
};
produkt prodobjekt; // dekl av ett objekt, en variabel av typen produkt
Märk att vi i båda fallen listar samma data. För klassen listar vi dessutom prototyper till funktioner som vi använder. Detta betyder då att de funktionerna har knutits samman med just dessa data. Data och funktioner som ingår i klassen kallar vi medlemmar.
I båda fallen har vi deklarerat en datatyp produkt. För struct produkt har vi sedan deklarerat en variabel, prodpost som då är ett faktiskt utrymme i minnet där data kan lagras. Vi kan också säga att prodpost är en instans av produkt.
Även klassen är en datatyp. För klasser gäller, precis som för alla andra datatyper att vi måste deklarera variabler för att vi faktiskt skall ha något att arbeta med. Märk att en datatyp, även en klass, enbart är en beskrivning av data medan en variabel är ett faktiskt utrymme för data i minnet. En variabel av klasstyp kallar vi objekt. Objektet är då en instans av klassen.
public: och private: kallas etiketter och anger hur olika medlemmar i ett objekt av klassen kan kommas åt, av utomstående funktioner eller endast av andra klassmedlemmar. Med utomstående menas då vanliga fristående funktioner och funktioner som är medlemmar i andra klasser. Det finns ytterligare en etikett som heter protected som ger samma skydd som private. Skillnaden visar sig när man använder det som kallas arv, dvs när man skapar underklasser till en klass. Detta kommer vi att tränga in i senare.
Funktionerna är deklarerade under etiketten public, vilket betyder att de kan anropas varifrån vi vill. Data ligger under etiketten private. Detta betyder att data inte är åtkomliga utanför klassen, de kan endast användas av de funktioner som tillhör klassen. Observera nu att det inte är nödvändigt att data är private och funktioner public. Oftast har vi inte data under rubriken public, eftersom vårt mål är att så långt möjligt skydda data mot oavsiktlig ändring. På det här sättet vet vi att vi inte kan ändra någonting i data utan att göra det via någon av funktionerna som tillhör klassen.
Däremot har man ofta funktioner som är private. Dessa kan då endast anropas av funktioner som är medlemmar i samma klass. Ett exempel skulle kunna vara följande:
När vi skapar en ny produkt så vill vi ha ett nytt produktnr. Vi kan anta att det senast använda produktnumret finns lagrat i en fil. Vi behöver alltså hämta det numret och öka det med ett för att få ett nytt nummer. Vi tänker oss en funktion nyttprodnr() som utför detta. Den anropas då inifrån funktionen nyprod. Deklaration av klassen blir då:
class produkt{
public:
void nyprod(char*); // publika medlemsfunktioner
void uppdat(float, int); // även kallade klassens gränssnitt
void skrivutprod();
float ge_pris ();
private:
int nyttprodnr(); // privat medlemsfunktion
int prodnr; // privata datamedlemmar
char benamning[20];
float pris;
int levtid;
};
produkt prodobjekt;
Datamedlemmarna i en klass är direkt åtkomliga för alla medlemsfunktioner utan att skickas som parametrar. Man kan säga att datamedlemmarna är globala inom klassen. Observera att public och privateetiketterna endast reglerar förhållandet mellan klassmedlemmar och utomstående funktioner.
Med gränssnitt menar vi de medel vi har för att kommunicera med ett objekt. Gränssnittet utgörs av de publika funktionerna och deras parametrar och returvärden. Funktionerna är möjligheten att få saker att hända i klassen och deras parametrar är vår väg att skicka in data utifrån till klassen. Via referensparametrar kan vi också få ut data från klassen liksom via returvärden.
Funktionen ge_pris i klassen produkt är ett exempel på det vi kallar en access-funktion, vars enda syfte är att hämta ut ett värde från en bestämd datamedlem. Funktionen gör bara en sak, den returnerar värdet från variablen pris. Detta medför att vi utifrån när som kan hämta ut detta värde utan att direkt kunna komma åt variabeln. Därmed har vi eliminerat risken för att värdet i pris förändras utan att vi ger ett direkt kommando om att detta skall ske via funktionen uppdat.
Märk att i klassdeklarationen angav vi bara prototyperna till funktionerna. Nu måste givetvis funktionerna definieras med de satser som utgör funktionskroppen. Funktionerna skrivs som varje annan funktion i programmet men med ett särskilt tillägg i funktionshuvudet som anger vilken klass de hör till. Funktionen ge_pris ovan skrivs så här:
float produkt::ge_pris(){
return pris;
}
Funktionen identifieras genom produkt::uppdat, dvs klassens namn, scopeoperatorn :: och funktionens eget namn. Märk att variabeln pris kan användas direkt inuti funktionen utan att skickas in som parameter.
Vi tar exemplet uppdat ur klassen produkt. Funktionen tar emot två värden på pris och levtid och ändrar dessa i det aktuella objektet. Värdena sänds in i funktionen utifrån vid anropet.
void produkt::uppdat(float nypris, int nylevtid){
pris = nypris;
levtid = nylevtid;
}
Det kan nu vara dags att sammanställa alltihop till ett litet testprogram för att få ett grepp om helheten.
#include <iostream.h>
#include <fstream.h>
#include <iomanip.h>
#include <string.h>
// Programmet läser in några data om en produkt och skriver sedan ut dessa
class produkt{
public:
void nyprod(char*); // publika medlemsfunktioner
void uppdat(float, int); // även kallade klassens gränssnitt
void skrivutprod();
float ge_pris ();
private:
int nyttprodnr(); // privat medlemsfunktion
int prodnr; // privata datamedlemmar
char benamning[20];
float pris;
int levtid;
};
// ********** funktionsdefinitioner för klassen produkt **************
void produkt::nyprod(char *bnamn){
prodnr = nyttprodnr();
strcpy (benamning,bnamn);
}
void produkt::uppdat(float nypris, int nylevtid){
pris = nypris;
levtid = nylevtid;
}
float produkt::ge_pris(){ // access funktion för pris
return pris;
}
void produkt::skrivutprod (){
cout << endl << endl;
cout << "Produktnr: " << prodnr << endl;
cout << "Benämning: " << benamning << endl;
cout << "Pris: " << pris << " kr" << endl;
cout << "Leveranstid: " << levtid << " dagar" << endl << endl;
}
int produkt::nyttprodnr(){
int pnr;
ifstream pnrin; // in o utstream för att läsa pnr o spara nytt pnr
ofstream pnrout;
pnrin.open("SistaPnr");
if (pnrin.fail()) // finns ingen fil troligen
pnr = 1;
else{
pnrin >> pnr;
pnrin.close();
pnr++;
}
pnrout.open("SistaPnr"); // spara det nya numret
pnrout << pnr;
pnrout.close();
return pnr;
}
//*************************************************************************
int main(){
produkt prodobjekt; // här deklarerar vi objektet som skall användas
char benamn[20];
float pris;
int ltid;
cout << endl;
cout << "Benämning på ny produkt: ";
cin >> benamn;
prodobjekt.nyprod(benamn); // vi anropar en funktion i ett objekt på
// detta sätt
cout << "Pris på produkten: "; // OBS att det är objektet o inte klassen
// som används här
cin >> pris;
cout << "Leveranstid dagar: ";
cin >> ltid;
prodobjekt.uppdat(pris, ltid);
cout << setiosflags (ios::showpoint | ios::fixed); // sätter format för
// utskr av float
cout << setprecision(2); // antal decimaler vid
// utskr av float
cout << endl << "Produktens pris är " << prodobjekt.ge_pris() << endl;
// visar hur ge_pris kan användas
prodobjekt.skrivutprod(); // skriver ut hela produkten
return 0;
}
Ovanstående program är bara en demonstration. För verkligt bruk saknas ju bl a möjligheten att spara inmatade data på fil. Programmet illustrerar emellertid hur vi definierar en klass och dess tillhörande funktioner samt hur ett objekt deklareras och hur funktionerna i klassen sedan kan anropas via objektet.
Märk särskilt följande: När vi definierar funktioner så använder vi oss av klassnamnet för att tala om vart funktionen hör. När vi anropar en funktion som vi gör i main i programmet så använder vi oss av objektnamnet. Det kan bara finnas en klass produkt i ett och samma program liksom en och samma datatyp, t ex en struct, endast kan finnas en gång. Däremot kan det finnas flera objekt av samma klass liksom det kan finnas flera olika postvariabler av samma struct-typ. Det är därför så att funktionen som anropas hör till en bestämd instans av klassen, det namngivna objektet.
Liksom varje annan datatyp kan även en klass användas för att skapa en vektor. Vi skapar en modifierad version av programexemplet från förra avsnittet för att illustrera.
#include <iostream.h>
#include <fstream.h>
#include <iomanip.h>
#include <string.h>
class produkt{
public:
void nyprod(int, char*); // publika medlemsfunktioner
void uppdat(float, int); // även kallade klassens gränssnitt
void skrivutprod();
float ge_pris ();
private:
int prodnr; // privata datamedlemmar
char benamning[20];
float pris;
int levtid;
};
// ******** funktionsdefinitioner för klassen produkt ***************
void produkt::nyprod(int pnr, char *bnamn){
prodnr = pnr;
strcpy (benamning,bnamn);
}
void produkt::uppdat(float nypris, int nylevtid){
pris = nypris;
levtid = nylevtid;
}
float produkt::ge_pris(){ // access funktion för pris
return pris;
}
void produkt::skrivutprod (){
cout << endl << endl;
cout << "Produktnr: " << prodnr << endl;
cout << "Benämning: " << benamning << endl;
cout << "Pris: " << pris << " kr" << endl;
cout << "Leveranstid: " << levtid << " dagar" << endl << endl;
}
//*************************************************************************
char meny (){ // fristående menyfunktion
char val;
cout << endl;
cout << "1. Ny produkt" << endl;
cout << "2. Uppdatera" << endl;
cout << "3. Prisinfo" << endl;
cout << "4. Skriv ut produkt" << endl;
cout << "0. Avsluta" << endl << endl;
cout << "> ";
cin >> val;
cout << endl;
return val;
}
int main(){
produkt prodobjekt[100]; // en vektor med 100 instanser av produkt
int pnr, ltid;
char benamn[20], val;
float pris;
while ((val = meny()) != '0')
switch (val){
case '1':
cout << "Produktnummer: ";
cin >> pnr;
cout << "Benämning på ny produkt: ";
cin >> benamn;
prodobjekt[pnr].nyprod(pnr, benamn);
// genom att indexera med pnr så arbetar vi mot rätt instans
// av produkt nämligen prodobjekt[pnr]
break;
case '2':
cout << "Produktnummer: ";
cin >> pnr;
cout << "Pris på produkten: ";
cin >> pris;
cout << "Leveranstid dagar: ";
cin >> ltid;
prodobjekt[pnr].uppdat(pris,ltid);
break;
case '3':
cout << "Produktnummer: ";
cin >> pnr;
cout << setiosflags (ios::showpoint | ios::fixed);
cout << setprecision(2);
cout << endl << "Produktens pris är "
<< prodobjekt[pnr].ge_pris() << endl;
break;
case '4':
cout << "Produktnummer: ";
cin >> pnr;
prodobjekt[pnr].skrivutprod();
break;
default:
cout << endl << "Val skall vara 0 - 4" << endl;
}
return 0;
}
Programmet är förändrat på följande punkter: Vi har inte någon automatisk generering av produktnummer. Programmet är menystyrt och olika operationer kan väljas. I stället för ett objekt har vi en vektor med 100 objekt av klassen produkt. Genom att indexera när vi anropar en operation kommer automatiskt data i rätt instans, dvs rätt vektorelement att behandlas.
Två särskilda funktioner kan läggas i varje klass. Constructorn är en funktion som körs automatiskt varje gång ett objekt skapas. Den används vanligen till att ge initialvärden till variabler eftersom det int går att initiera variabler på vanligt sätt när de är klassmedlemmar. Constructorn har inte någon datatyp och har samma namn som klassen.
Destructorn körs automatiskt när ett objekt försvinner, dvs vanligast när en funktion där objektet deklarerats just avslutas. Destructor används mera sällan och vanligen för att då lämna tillbaka minne som allokerats (se längre fram om pekare).
Vi tar ett exempel för vårt program ovan där vi bestämmer att prodnr skall sättas till 0 och benämning på produkten skall sättas till "xxxxx" i alla element innan något inmatats. Klassen får följande utseende:
class produkt{
public:
produkt (); // constructor för klassen, ingen datatyp
void nyprod(int, char*); // publika medlemsfunktioner
void uppdat(float, int); // även kallade klassens gränssnitt
void skrivutprod();
float ge_pris ();
private:
int prodnr; // privata datamedlemmar
char benamning[20];
float pris;
int levtid;
};
Constructor-funktionen produkt definieras sedan på följande sätt på samma ställe som de övriga funktionerna för klassen. Observera att ingen typ anges för funktionen.
produkt::produkt(){ // constructor för klassen produkt
prodnr = 0;
strcpy (benamning,"xxxxx");
}
För varje nytt objekt som skapas, dvs för vart och ett av de 100 objekten i vektorn körs funktionen produkt automatiskt vid etablerandet och de önskade värdena tilldelas.
I exemplet använder vi en klass som enbart har medlemmar som är variabler. Nedanstående skulle emellertid fungera på en klass som även innehåller funktioner. Funktionerna tar inte upp något minnesutrymme i klassen. Deklarationen av funktionerna är enbart ett sätt att knyta dessa till klassen som medlemmar och innebär inte att de därmed ingår i klassens minnesutymme rent fysiskt. Detta kan testas genom att deklarera två klasser med och utan funktioner men med samma dataelement. Om man sedan använder operatorn sizeof på båda klasserna visar det sig att de har samma storlek.
#include <iostream.h>
#include <fstream.h>
class post{ // vi använder en class som en ren datapost
public:
int nr;
char namn[20];
};
void Enterpost(post &p){
cout << "Nr: ";
cin >> p.nr;
if (p.nr != 0){
cout << "Namn: ";
cin >> p.namn;
}
}
int main(){
post Post;
ofstream strout("testfil", ios::out);
Enterpost(Post);
while (Post.nr!=0){
strout.write((char *)&Post,sizeof(Post));
// write krÆver en adress av typ char *
Enterpost (Post);
}
strout.close();
return 0;
}
Satsen "strin.write((char*)&Post,sizeof(Post));" kräver en viss förklaring. write kräver som första parameter en adress till data som skall skrivas ut och då i form av en pekare till char. &-tecknet som det här placerats betyder adressen till variabeln Post. (char *) är det vi kallar för en typecast dvs omvandling från pekare (adress) till typ post till pekare till char. Som andra argument kräver write antal bytes som skall skrivas. Detta får vi med den särskilda operatorn sizeof som ger storleken av datatyper och variabler.
Det kan påpekas att det inte hade varit någon skillnad om vi istället hade använt en struct post. Så länge en klass enbart innehåller data skiljer den sig i det här hänseendet inte från en struct.
Nästa exempel visar hur poster kan läsas.
#include <iostream.h>
#include <fstream.h>
class post{ // vi använder en class som en ren datapost
public:
int nr;
char namn[20];
};
void Printpost(post p){
cout << "Nr: "
<< p.nr << endl;
cout << "Namn: "
<< p.namn << endl;
}
int main(){
post Post; // ett objekt av klassen post
ifstream strin("testfil", ios::in);
strin.read((char*)&Post,sizeof(Post));
// read krÆver som typ en adress av typ char *
while (! strin.eof()){
Printpost (Post);
strin.read((char*)&Post,sizeof(Post));
}
strin.close();
return 0;
}
Ett påpekande bör göras. En särskild finess i C++ är möjligheten att skapa funktioner som bildar nya varianter av operatorer. Det är vanligt att man skapar helt egna in- och utmatningsoperatorer för klasser. Då gör man en funktion som skriver ut data från en klass fält för fält till en fil, varvid det inte spelar någon roll om klassen också innehåller funktioner och data som inte skall ut till eller in från fil. Slutresultatet blir att man skriver och läser data till sina klasser med operatorerna >> och <<.
Följande kapitel består huvudsakligen av programexempel.
Nedanstående visar ett mycket enkelt exempel på arvsmekanismen. Två funktioner och två variabler definieras i basklassen. Dessa ärvs sedan av varje subklass. I subklasserna finns egna funktioner för det specifika för varje klass, nämligen inmatningen av figurens attribut och beräkningen av area och omkrets. I fallet kvadrat drar vi nytta av att den är ett specialfall av rektangel och gör en subklass till Rektangel där vi enbart definierar en egen inmatning och använder beräkningen från Rektangel som ärvts.
#include <iostream.h>
#include <ctype.h>
const float pi=3.1416;
//----------------------- basklass för samtliga figurklasser -------------
class Figur{
public:
double hamta_area();
double hamta_omkrets();
protected:
double area;
double omkrets;
// protected, ej private, om de skall kunna ärvas till Kvadrat
};
// Cirkel och Rektangel ärver hamta_area och hamta_omkrets
// samt area och omkrets från Figur
//----------------------- subklasser till Figur ---------------------------
class Cirkel : public Figur{
public:
void ange_attribut();
private:
void kalkylera(double);
};
class Rektangel : public Figur{
public:
void ange_attribut();
protected:
void kalkylera(double, double);
// protected, ej private, om den skall kunna ärvas till Kvadrat
};
//----------------------- subklass till Rektangel ---------------------------
class Kvadrat : public Rektangel{
public:
void ange_attribut();
};
//####################### Funktionsdefinitioner #############################
//*********************** medlemsfunktioner *************************
//------------ funktionsdefinitioner för figur ------------
double Figur::hamta_area(){
// acessfunktion för areavärdet
return area;
}
double Figur::hamta_omkrets(){
//accessfunktion för omkretsvärdet
return omkrets;
}
//------------ funktionsdefinitioner för Cirkel ------------
void Cirkel::ange_attribut(){
// läser in cirkelns radie och anropar kalkylera(radie)
double radie;
cout << "Radie: ";
cin >> radie;
kalkylera (radie);
}
void Cirkel::kalkylera (double radie){
// anropas från ange_attribut, beräknar area och omkrets av en cirkel
// parametrar: radie - positivt reellt tal
// resultat placeras i klassens variabler area och omkrets
area=radie*radie*pi;
omkrets=radie*2*pi;
}
//------------ funktionsdefinitioner för Rektangel ------------
void Rektangel::ange_attribut(){
// läser in rektangelns sidor och anropar kalkylera(sid1, sid2)
double sid1, sid2;
cout << "Långsida: ";
cin >> sid1;
cout << "Kortsida: ";
cin >> sid2;
kalkylera (sid1, sid2);
}
void Rektangel::kalkylera (double sid1, double sid2){
// anropas från ange_attribut, beräknar area och omkrets av en rektangel
// parametrar: sid1, sid2 - positiva reella tal
// resultat placeras i klassens variabler area och omkrets
area=sid1*sid2;
omkrets=(sid1+sid2)*2;
}
//------------ funktionsdefinitioner för Kvadrat ------------
void Kvadrat::ange_attribut(){
// läser in kvadratens sida och anropar kalkylera(sid, sid)
double sid;
cout << "Sida: ";
cin >> sid;
kalkylera (sid, sid);
}
//************ separata hjälpfunktioner ************
void list_meny(){
// anropas från main
// listar menyvalen på skärmen
cout << "-------------------------" << endl;
cout << "R)ektangel" << endl
<< "C)irkel" << endl
<< "K)vadrat" << endl
<< "A)vsluta";
cout << endl << "Välj: ";
}
//*********************** main *************************
int main(){
// menystyrd huvudloop för programmet
Cirkel cirkel; // ett objekt av class Cirkel
Rektangel rektangel; // ett objekt av class Rektangel
Kvadrat kvadrat; // ett objekt av class Kvadrat
char val;
list_meny();
cin >> val;
while ((val=toupper(val))!='A'){
switch(val){
case 'C':
cirkel.ange_attribut();
cout << "Area: " << cirkel.hamta_area() << endl;
cout << "Omkrets: " << cirkel.hamta_omkrets() << endl;
break;
case 'R':
rektangel.ange_attribut();
cout << "Area: " << rektangel.hamta_area() << endl;
cout << "Omkrets " << rektangel.hamta_omkrets() << endl;
break;
case 'K':
kvadrat.ange_attribut();
cout << "Area: " << kvadrat.hamta_area() << endl;
cout << "Omkrets " << kvadrat.hamta_omkrets() << endl;
break;
case 'A':
default:
cout << "Felaktigt val" << endl;
}
list_meny();
cin >> val;
}
return 0;
}
Exemplet nedan är en modifiering av exempel 8. Skillnaden är att vi skapat en särskild utskriftsfunktion i basklassen som omdefinierar utström-operatorn << för klassen. Inuti funktionen skrivs värdena ut på samma sätt som tidigare gjordes i main. I main sätter vi nu in objektets namn i en cout-sats vilket leder till att utskrift sker.
När vi omdefinierar << operatorn måste detta ske genom en friend-funktion. En operatorfunktion som är medlem i en klass får bara ha en parameter och den måste vara av typ referens till klassen själv. En opperatorfunktion som är fristående kan ha två parametrar som kan vara referenser till olika klasser. I detta fall handlar det om att hämta data från ett objekt av en klass och skicka till en annan, nämligen klassen ostream som är den klass som används för att deklarera cout.
I exemplet visas huvdsakligen de delar som har ändrats från föregående program.
//----------------------- basklass för samtliga figurklasser -------------
class Figur{
public:
// accessfunktionerna är borta och ersatt med en streamoperatorfunktion
friend ostream& operator<<(ostream&, Figur&);
protected:
double area;
double omkrets;
// protected, ej private, om de skall kunna ärvas till Kvadrat
};
// Cirkel och Rektangel ärver hamta_area och hamta_omkrets
// samt area och omkrets från Figur
//----------------------- subklasser till Figur ---------------------------
class Cirkel : public Figur{
public:
void ange_attribut();
private:
void kalkylera(double);
};
class Rektangel : public Figur{
public:
void ange_attribut();
protected:
void kalkylera(double, double);
// protected, ej private, om den skall kunna ärvas till Kvadrat
};
//----------------------- subklass till Rektangel ---------------------------
// subklass till Rektangel
class Kvadrat : public Rektangel{
public:
void ange_attribut();
};
//####################### Funktionsdefinitioner #############################
//************ friendfunktion för Figur ************
// följande funktion omdefinierar << för klassen figur
// och därmed för alla subklasser
ostream& operator<<(ostream& ut, Figur& fig){
// utskrift av area och omkrets för figur
ut << "Area: " << fig.area << endl;
ut << "Omkrets " << fig.omkrets << endl;
return ut;
}
//************ medlemsfunktioner ************
// medlemsfunktionerna är desamma utom att funktionerna
// hamta_area och hamta_omkrets för Figur nu utgår
//************ separata hjälpfunktioner ************
void list_meny(){
// ...
}
//************ main ************
int main(){
// menystyrd huvudloop för programmet
Cirkel cirkel; // ett objekt av class Cirkel
Rektangel rektangel; // ett objekt av class Rektangel
Kvadrat kvadrat; // ett objekt av class Kvadrat
char val;
list_meny();
cin >> val;
while ((val=toupper(val))!='A'){
switch(val){
case 'C':
cirkel.ange_attribut();
cout << cirkel << endl;
// notera hur hela objektet skickas till cout med operatorn <<
break;
case 'R':
rektangel.ange_attribut();
cout << rektangel << endl;
break;
case 'K':
kvadrat.ange_attribut();
cout << kvadrat << endl;
break;
case 'A':
default:
cout << "Felaktigt val" << endl;
}
list_meny();
cin >> val;
}
return 0;
}
Det visade exemplet med sin modifiering här är så enkelt att det förefaller som det är onödigt med alla dessa klasser och funktioner för att skapa ett program för några få simpla beräkningar. Värdet i detta ligger emellertid i sättet att se på programmets möjligheter för förändringar och utökningar. Genom att bygga ut hierarkin med flera subklasser kan man lätt skapa fler figurer och vara säkra på att detta sker utan bieffekter i andra delar av programmet. Vidare kan vi modifiera varje enskild klass utan att övriga berörs. Vill vi t ex för rektangel beräkna diagonalen så går det utmärkt att göra utan att förändra något i övriga klasser. Däremot behöver vi tillfoga en egen operator<< för denna subklass som då överlagrar den som finns i basklassen.
Som avslutning visas nu ett utökat exempel där vi tillfört utskrift av diagonal för rektangel och därmed också för kvadrat. Dessutom har klassen triangel tillförts.
#include <iostream.h>
#include <ctype.h>
#include <math.h>
const float pi=3.1416;
//----------------------- basklass för samtliga figurklasser -------------
class Figur{
public:
friend ostream& operator<<(ostream&, Figur&);
protected:
double area;
double omkrets;
// protected, ej private, om de skall kunna ärvas till Kvadrat
};
// Subklasser ärver hamta_area och hamta_omkrets samt area och omkrets från Figur
//----------------------- subklasser till Figur ---------------------------
class Cirkel : public Figur{
public:
void ange_attribut();
private:
void kalkylera(double);
};
class Rektangel : public Figur{
public:
void ange_attribut();
friend ostream& operator<<(ostream&, Rektangel&);
// denna överlagrar operator<< från basklassen
// i Rektangel och därmed även i kvadrat
protected:
void kalkylera(double, double);
double diagonal;
// protected, ej private, om den skall kunna ärvas till Kvadrat
};
class Triangel : public Figur{
public:
void ange_attribut();
private:
void kalkylera(double, double, double);
};
//----------------------- subklass till Rektangel ---------------------------
// subklass till Rektangel
class Kvadrat : public Rektangel{
public:
void ange_attribut();
};
//####################### Funktionsdefinitioner #############################
//************ friendfunktion för Figur ************
ostream& operator<<(ostream& ut, Figur& fig){
// utskrift av area och omkrets för figur
ut << "Area: " << fig.area << endl;
ut << "Omkrets " << fig.omkrets << endl;
return ut;
}
//************ friendfunktion för Rektangel ************
//Denna funktion tillförs för att kunna skriva ut även diagonalen för rektangel
ostream& operator<<(ostream& ut, Rektangel& fig){
// utskrift av area och omkrets för figur
ut << "Area: " << fig.area << endl;
ut << "Omkrets: " << fig.omkrets << endl;
ut << "Diagonal: " << fig.diagonal << endl;
return ut;
}
//************ medlemsfunktioner ************
//------------ funktionsdefinitioner för Cirkel ------------
void Cirkel::ange_attribut(){
// läser in cirkelns radie och anropar kalkylera(radie)
double radie;
cout << "Radie: ";
cin >> radie;
kalkylera (radie);
}
void Cirkel::kalkylera (double radie){
// anropas från ange_attribut
// beräknar area och omkrets av en cirkel
// parametrar: radie - positivt reellt tal
// resultat placeras i klassens variabler area och omkrets
area=radie*radie*pi;
omkrets=radie*2*pi;
}
//------------ funktionsdefinitioner för Rektangel ------------
void Rektangel::ange_attribut(){
// läser in rektangelns sidor och anropar kalkylera(sid1, sid2)
double sid1, sid2;
cout << "Långsida: ";
cin >> sid1;
cout << "Kortsida: ";
cin >> sid2;
kalkylera (sid1, sid2);
}
void Rektangel::kalkylera (double sid1, double sid2){
// anropas från ange_attribut
// beräknar area och omkrets av en rektangel
// parametrar: sid1, sid2 - positiva reella tal
// resultat placeras i klassens variabler area och omkrets
area=sid1*sid2;
omkrets=(sid1+sid2)*2;
diagonal=sqrt((sid1*sid1)+(sid2*sid2));
}
//------------ funktionsdefinitioner för Triangel ------------
void Triangel::ange_attribut(){
// läser in triangelns sidor och anropar kalkylera(sid1, sid2)
double sida, sidb, sidc;
cout << "Sida a: ";
cin >> sida;
cout << "Sida b: ";
cin >> sidb;
cout << "Sida c: ";
cin >> sidc;
kalkylera (sida, sidb, sidc);
}
void Triangel::kalkylera (double a, double b, double c){
// anropas från ange_attribut
// beräknar area och omkrets av en rektangel
// parametrar: sid1, sid2 - positiva reella tal
// resultat placeras i klassens variabler area och omkrets
double cosA, A;
cosA=(b*b+c*c-a*a)/(2*b*c);
A=acos(cosA);
area=(b*c*sin(A))/2;
omkrets=a+b+c;
}
//------------ funktionsdefinitioner för Kvadrat ------------
void Kvadrat::ange_attribut(){
// läser in kvadratens sida och anropar kalkylera(sid, sid)
double sid;
cout << "Sida: ";
cin >> sid;
kalkylera (sid, sid);
}
//************ separata hjälpfunktioner ************
void list_meny(){
// anropas från main
// listar menyvalen på skärmen
cout << "-------------------------" << endl;
cout << "R)ektangel" << endl
<< "C)irkel" << endl
<< "K)vadrat" << endl
<< "T)riangel" << endl
<< "A)vsluta";
cout << endl << "Välj: ";
}
//************ main ************
int main(){
// menystyrd huvudloop för programmet
Cirkel cirkel; // ett objekt av class Cirkel
Rektangel rektangel; // ett objekt av class Rektangel
Kvadrat kvadrat; // ett objekt av class Kvadrat
Triangel triangel; // ett objekt av class Triangel
char val;
list_meny();
cin >> val;
while ((val=toupper(val))!='A'){
switch(val){
case 'C':
cirkel.ange_attribut();
cout << cirkel << endl;
break;
case 'R':
rektangel.ange_attribut();
cout << rektangel << endl;
break;
case 'K':
kvadrat.ange_attribut();
cout << kvadrat << endl;
break;
case 'T':
triangel.ange_attribut();
cout << triangel << endl;
break;
case 'A':
default:
cout << "Felaktigt val" << endl;
}
list_meny();
cin >> val;
}
return 0;
}